大模型辅助 Bilibili 视频内容概览(一)
因为事务繁忙,最近我对 ai 智能总结产生了兴趣,做了几次总结之后发现效果还不错,这里做一个初版的记录,之后会逐步完善整个工作流。
目前的 demo 自动化的程度并不高,目前的工作流程如下:
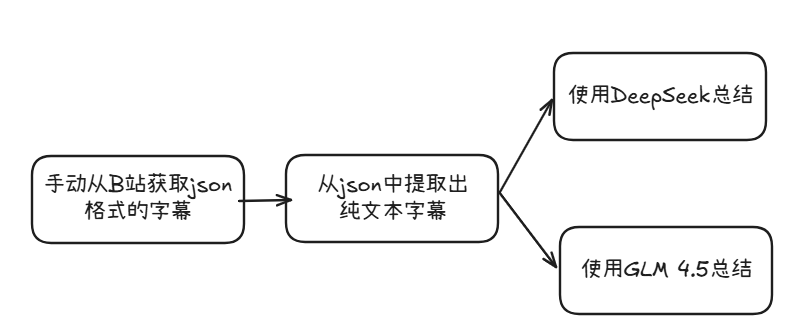
首先设计一个从 json 文件中提取目标文本的函数,在提取之前,我们要先观察一下 json 的格式:
{
"font_size": 0.4,
"font_color": "#FFFFFF",
"background_alpha": 0.5,
"background_color": "#9C27B0",
"Stroke": "none",
"type": "AIsubtitle",
"lang": "zh",
"version": "v1.7.0.4",
"body": [
{
"from": 0.0,
"to": 0.24,
"sid": 1,
"location": 2,
"content": "Hello",
"music": 0.0
},
{
"from": 0.24,
"to": 0.64,
"sid": 2,
"location": 2,
"content": "大家好",
"music": 0.0
},
{
"from": 509.08,
"to": 509.5,
"sid": 201,
"location": 2,
"content": "拜拜",
"music": 0.0
}
]
}于是设计提取函数如下:
def extract_subtitles(json_path: str, output_path: str = None):
json_file = Path(json_path)
if not json_file.exists():
print(f"[!] 文件不存在: {json_file}")
return None
with open(json_file, "r", encoding="utf-8") as f:
data = json.load(f)
body = data.get("body", None)
if not body:
print("[!] JSON中未找到 'body' 字段,可能不是字幕文件格式。")
return None
subtitles = [entry.get("content", "").strip() for entry in body if "content" in entry]
text = "\n".join(subtitles)
if not output_path:
output_path = json_file.with_suffix(".txt")
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(f"[+] 提取完成:{output_path}")
return output_path将提取到的内容单行保存在 content.txt 中,然后调用 deepseek-chat,glm-4.5-flash 模型二选一进行总结,前者需要付费,后者在一定额度内免费使用。经过测试,两者的准确度相差不打大,所以默认使用后者进行总结。
提示词使用如下,因为我会挑选一部分写入博客,所以预留了一个标题的位置:
messages=[
{
"role": "system",
"content": (
"你是一个有用的AI助手,现在请你对如下文本进行总结,要求语言精炼并保持原意。\n\n"
"【输出格式要求】\n"
"- 使用 Markdown 形式输出\n"
"- 顶层标题统一使用“##”\n"
"- 二级标题统一使用“###”\n"
"- 不得修改原文本含义,仅优化结构与表达"
),
},
]前两次 ai 总结内容同样在博客里,这里给出链接:
在实际使用的过程中感官还算可以,但是手动操作过于麻烦;而且部分 B 站视频没有相应的字幕,或者音频模糊,导致文本出现偏差的问题,后续将从这两个方向继续完善。