大模型辅助 Bilibili 视频内容概览(二)
在上一篇大模型辅助总结的文章中,笔者提出两个问题:
- 手动操作过于麻烦,希望能够添加爬虫实现一键拉取功能
- 部分 B 站视频没有相应的字幕,或者音频模糊,导致文本出现偏差的问题。
今天笔者对问题一实现了脚本修正:
首先为了模块清晰,笔者对之前的脚本进行了分文件处理,同时添加了自动爬取的模块,现在的代码架构如下:
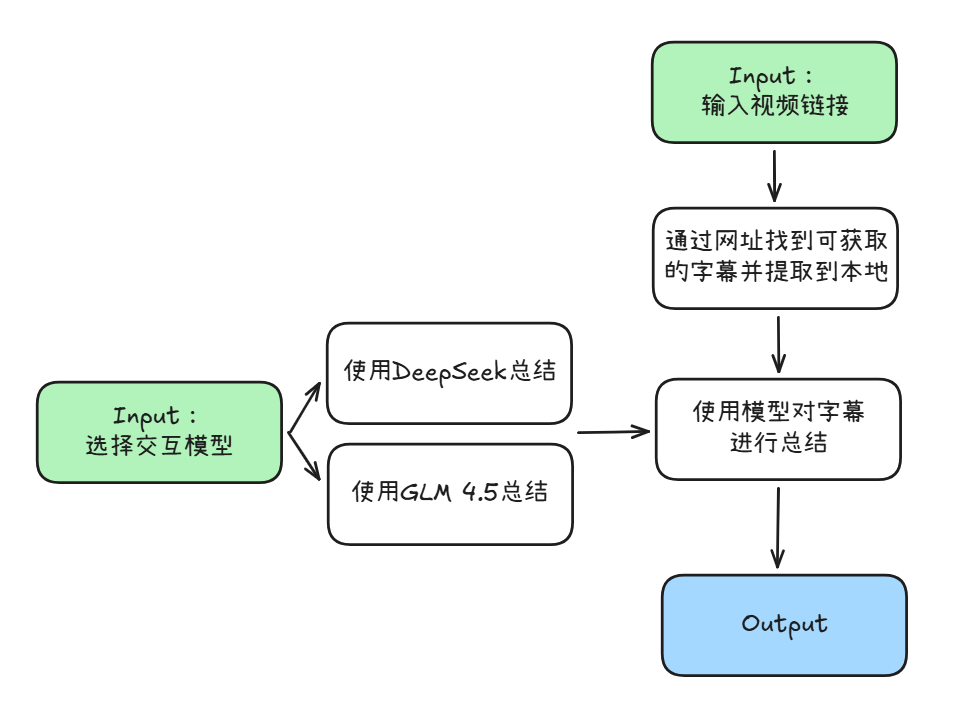
原来的一个文件被分为了四个:
[Bili_ai_fast_get]
deepseek_llm.py
get_subtitle.py
main.py
zhipu_llm.py这里简化了手动从网页中拉取 json 的步骤,转为直接通过输入的链接自动提取 BV 号并解析,获取字幕接口并将提取到的字幕保存到本地文件中。
关键代码如下:
import json
import requests
import re
def fetch_and_save_subtitles(bvnane: str, file_name: str = "content.txt"):
# 目标网址和请求头
headers = {
"Cookie": "", # 填自己的
"Origin": "https://www.bilibili.com",
"User-Agent": "" # 填自己的
}
# 视频的 URL
pp = "0"
url = f"https://www.bilibili.com/video/{bvnane}/?spm_id_from=333.1007.tianma.1-2-2.click&vd_source=efbc10526f5fa5642530923cf09ce506&p={pp}"
# 发送HTTP请求获取页面
response = requests.get(url, headers=headers)
# 提取 aid 和 cid
aid_match = re.findall(r'.*,"aid":(\d+),', response.text)
cids_match = re.findall(rf'"{bvnane}","cid":(\d+),', response.text)
if aid_match and cids_match:
aid = aid_match[0]
cid = cids_match[0]
print(f"aid: {aid}, cid: {cid}")
# 获取字幕接口 URL
hturl = f"https://api.bilibili.com/x/player/wbi/v2?aid={aid}&cid={cid}"
print(f"[+]请求字幕接口: {hturl}")
# 发送第二次请求
response2 = requests.get(hturl, headers=headers)
# 提取字幕url
pattern = r'"subtitle_url":"(.*?)","subtitle_url_v2"'
match = re.search(pattern, response2.text)
if match:
subtitle_url = match.group(1)
print(f"[+]字幕 URL: https:{subtitle_url}")
# 请求字幕文件
uul = f"https:{subtitle_url}"
responses1 = requests.get(uul, headers=headers)
# 解析字幕文件数据
data = json.loads(responses1.text)
# 提取 content 内容
contents = [item['content'] for item in data['body']]
# 将每一句话写入到文本文件
with open(file_name, "w", encoding="utf-8") as file:
for line in contents:
file.write(f"{line}\n")
print(f"[+]已将字幕内容保存到 {file_name} 文件。")
return file_name
else:
print("[!]未找到字幕 URL")
return ""
else:
print("[!]未能提取到 aid 或 cid")
return ""目前需要完善的部分如下:
- 实现批量总结。
- 对音频模糊但是有字幕的视频实现OCR文字识别。
- 对音频模糊且难以提取字幕的视频尝试修复。
- 对论文导读类视频的拆解,只提取笔者感兴趣的部分,其他全部丢弃,对接收信息进行提纯。
- 对过长的内容可能需要进行预处理,节省token的同时,提高大模型提炼的准确度。
下一次讲讲简单的 OCR 功能实现,以及整合过程中的一些问题(等我把问题解决完先)